Background
With obesity rising as a global health crisis, early risk detection is crucial for prevention. This project aimed to leverage machine learning to predict obesity risk levels based on lifestyle and genetic factors, providing a proactive healthcare tool.
Methods
- Collected and cleaned Kaggle dataset (populations from Mexico, Peru, Colombia).
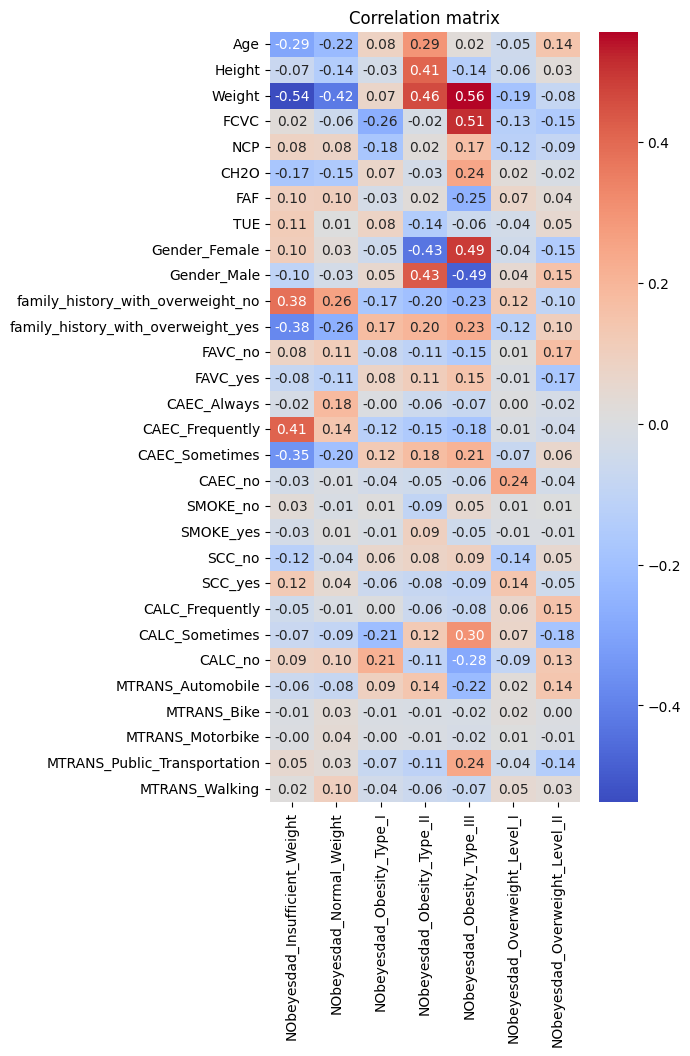
- Performed exploratory data analysis (EDA) with correlation heatmaps, histograms, and feature importance analysis.
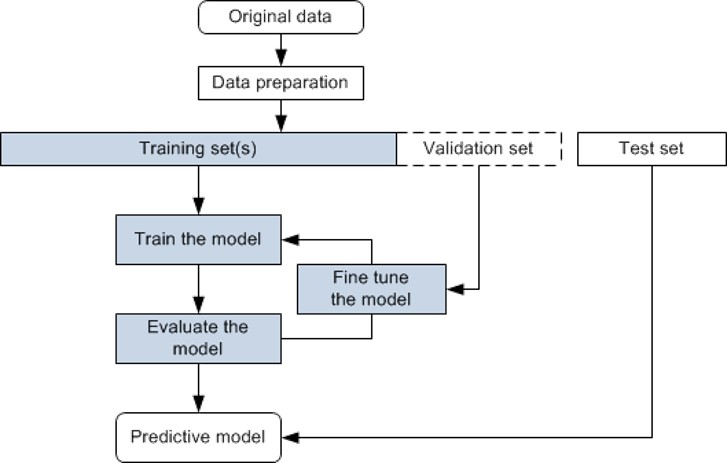
- Preprocessed data (encoding categorical features, scaling, handling missing values).
- Trained three models: Random Forest, KNN, and CNN, including hyperparameter tuning via Grid Search and Randomized Search.
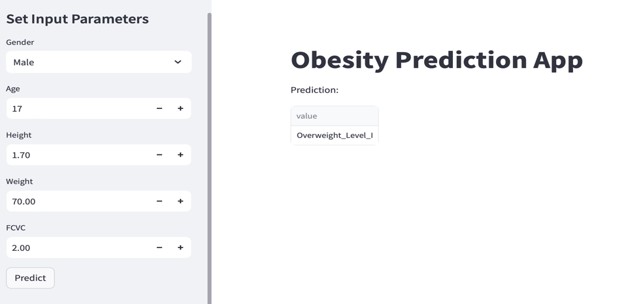
- Built a Streamlit web app for user interaction with the trained model.
Key Results
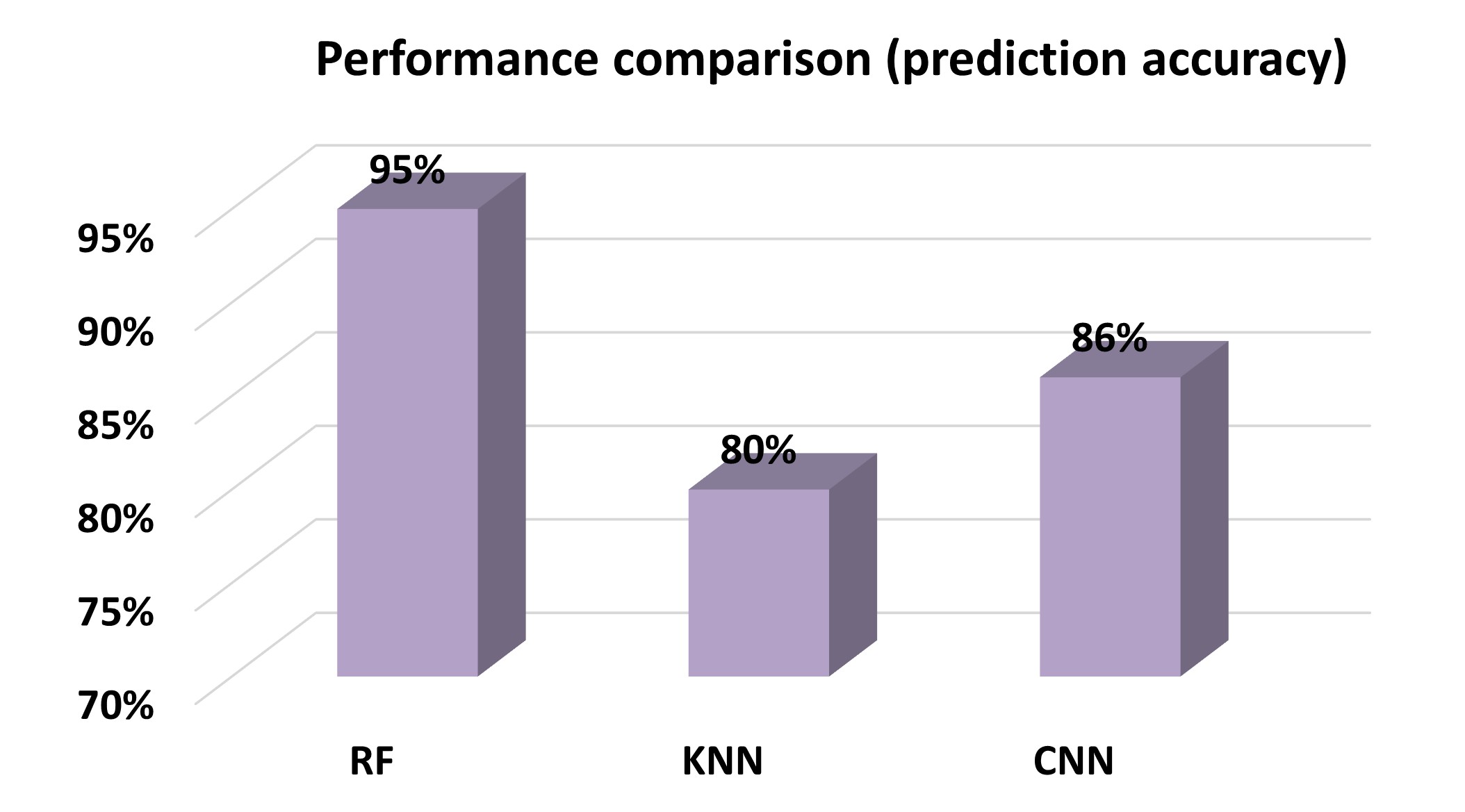
- Random Forest achieved the highest accuracy (~95%), outperforming CNN (~86%) and KNN (~80%).
- Identified top predictive features: frequency of vegetable consumption, number of main meals, height, weight, and screen time.
- The Streamlit app allowed users to input lifestyle parameters and receive obesity risk classification in real-time.